
Technical Documentation at Upvest
The product engineering teams at Upvest were already doing a good job of writing product documentation before I started at Upvest in July of 2022. That’s a testament to Upvest’s commitment to finding “product-minded” engineers and supporting them with dedicated “Product Managers”. I can’t stress enough how important that is to our outcomes. Despite this, I spent a lot of time and effort over the last six months, working on documentation. Not specifically writing documentation, but mainly defining the processes, responsibilities and tooling around the documentation and attending to the implementation of all this.
If the documentation and the mindset were already good, why invest so heavily in this area?
The short answer is that the development and provision of technical documentation is one of the core pillars of Developer Experience at Upvest. In my opinion, great documentation is job number one for any Developer Experience team worth their salt, no matter if they’re internally or externally focused.
Why do I think that? There’s a lot to explain, but if you’ve got time for a long read, please do read on…
Engineers love (hate?) documentation
Software developers have an uneasy relationship with documentation. A lot of engineers simply dislike writing documentation. I’ve heard (and made!) lots of rationalisations for not needing to write documentation. There’s sometimes a view that it is not as important as the features under development, or that it isn’t (or shouldn’t) be part of an engineer’s job. I side a little with that latter view, delivering documentation to the correct quality does require a specific skill set that engineers often lack. The fact remains though, the originators of the functionality are the engineering teams and, in our case, their attendant product folks. So at least part of this work has to start with those teams.


Engineers might also argue that reference documentation, generated from source code, is enough. I disagree strongly with this view.
I’ve also encountered a small subset of engineers who buy into “the code is the documentation”. Though that view rarely exists where external developers interact with the software, and that software is not Open Source. It certainly isn’t the case at Upvest.
Like many practices in software engineering, only real experience of being on the other side of the relationship focuses our minds on why we need to do these things. How do customers approach integration when they approach the system for the first time? More broadly, what do engineers do at the beginning of developing against software provided in general?
In most cases, they look for documentation. People never choose to do things the hard way. Prose documentation in the form of guides and tutorials takes the hard work out of getting started.
The use cases of technical documentation
With my “Developer Experience” hat on, I tend to think about that by exploring the use cases consumers of software might have when attempting to interact with it at the code level. This can mean directly as a maintainer of the code but, at Upvest, it means as a customer trying to build a product around the Upvest Investment API. By extrapolating out from those use cases we can define the types of materials we need to provide. These are the classes of documentation we currently seek to provide:
Tutorials
As we already discussed, tutorials allow the developer to take their first steps with a product in a secure, guided manner, without the formality, scheduling and personnel required for a training session. They are, by definition learning-oriented. Giving your users a route into the way of working and an overview of the system as a whole. They provide for their needs in a self-service manner. I’ll return to why that is important a little later.
How-To Guides
The second kind of prose documentation is guide material. Guides present topic-specific areas where an engineer might look to develop their use of the product further. They are task-oriented and should explore their subject more deeply than a tutorial, and provide examples of how to implement it.
Reference
Do we still need reference materials then? Yes, of course. They once again meet a different set of use cases. Once you know your way around the system you’ll often want to look up something you half remembered quickly. Reference materials are easier to scan through than raw source code and, in many scenarios, more likely to be available to 3rd party engineers. They can also drive, for example, in-line help in IDEs. They are information-oriented, reminding you about something you’re already aware of rather than providing guidance.
Explanation
So, do we have everything covered with these three types of documentation then? No, else why would I have added this section? :-D Tutorials, guides, reference material, and even source code can’t provide a complete set of information needed to understand some software in context. There are all kinds of concepts, constraints and decisions reflected in a piece of software that aren’t explicitly communicated in its code.
Part of the art of documentation is ’loading’ this information into a customer’s brain at the point they need it. If you try to transfer it all at once you will confound the reader. Some contextual information is important to know before you wade into a topic, and some is only necessary when you delve deeper. The former has a place in a tutorial or guide, and the latter is perhaps only mentioned in passing or exists only as a background explanation document.
Diátaxis
I didn’t invent this breakdown of documentation by use case. It’s called Diátaxis and it’s being used at a number of companies that I rate as having the best developer documentation.
Documentation is key to controlling your Developer Experience
OK, so perhaps you can appreciate why these classes of documentation are useful. Is it really essential though? What happens if your users can’t find introductory materials, or don’t have useful reference material to hand?
They’ll start to search elsewhere for help.



If you have a contractual support arrangement with your users they might come directly to you and ask for support. In the general case that’s actually not that likely, and less likely still if you provide a widely used tool, open source or otherwise. Harvard Business Review’s data tells us that, across all business sectors, 81% of customers will try self-service solutions before reaching out for human assistance.
So what does this look like?
Well, what would you do? You’d likely pull up your favourite search engine and search for help. For a lot of software, you’ll find blog posts, forum entries, and answers on dedicated technology sites. All of this might be useful, but as an originator of software products, you should realise that the void, where your documentation should have been, is now filled by “Shadow documentation”. “Shadow documentation” is outside your control. You cannot correct it, update it or even remove it. In effect, you’ve lost control of your Developer Experience.
Whether such phenomena occur depends largely on how widely used your software is. I think it’s fair to say that this situation doesn’t exist (yet!) for Upvest. In this case, prevention is much better than a cure.
The role of technical support
Let’s continue this path a little further. What will happen if no quick or useful answers can be found on the internet at large?
Experienced engineers might have some intuitions about what tasks they need to do first, but that same experience might also prompt them to jump to the next stage: asking for help.
The arguments for doing a great job responding to support enquiries are fairly obvious. Asking for help follows a similar pattern to looking for documentation. If you provide it to customers, and you provide it well, then your users will come to you for help, and you will be in control of that experience.
If you don’t provide support in an easily accessible way, or in a form your user don’t appreciate, then they may well go back to those 3rd party forums and ask for help there.
Community or public forum support is a double-edged sword. It reduces the load on your own support staff, but it contributes further to the “shadow documentation” problem.
So this is rather a large and dangerous tar pit to let your users fall into. If you fall at the first hurdle, then you’re in a fight to regain control of your Developer Experience.



Support doesn’t scale easily
There’s another problem with falling back to customer support enquiries. Direct support, human to human, scales really badly. If your user base scales the amount of support you have to provide scales as a function of the number of users. Relying on your staff to provide this support is expensive both in terms of the number of people you’re paying to do it, and in the case of 2nd and 3rd line support, the other tasks you’re pulling them away from.
As an engineer, presented with a human process that doesn’t scale up, what’s my go-to tool? Automation.
How do we automate support and learning?
You probably already know where I’m going here. Yes. If you don’t want your working life to disappear into an abyss of customer support questions, if you want to control your Developer Experience and if you want your customers to be satisfied with every aspect of what you do, then you need to take documentation seriously.
To borrow a pithy line: “Documentation is automation”.
Every time a customer finds a solution in an obvious place in the documentation they’re having a positive, self-service experience. They’ll feel good about your product, and they’ll generate less “busy work” for your staff in supporting them. All of this is achieved using a mechanism that scales trivially and at a very low cost.
If I’m preaching to the converted then you’ll be nodding along at this point, but let’s just pause a second and give credence to the technophilic and graphopobic amongst the audience.
One modern solution to this question might be “Have a bot handle support duty!”. I’m sure we’re all well aware of what has become possible with modern machine-learning technology. Your readiness to trust such a system might vary, but it’s definitely worthy of consideration. However, even machine learning needs source material to learn from. It’s turtles all the way down I’m afraid!
In a very real sense, a document that is easily discovered and easily consumed, is every bit as useful as the fancy bot, and a more positive self-service experience for the customer.
But documentation rots!
If you write the documentation, then you change the code without changing the documentation then your documentation will be out of date. It’s another of those rationalisations that are made for not writing documentation. Why bother when it’s just going to be wrong soon?
In response, I’m fond of telling people that documentation that doesn’t match the functionality of the product is a bug. Not just a bug, a “Stop the line” bug.
From the customer’s point of view, there’s often no difference between functionally correct code with incorrect documentation and functionally incorrect code with correct documentation. Both cases will waste their time and erode the trust they have in your software.
Does this mean that you shouldn’t write the documentation in the first place?
No, it does not. We’ve set out above exactly why documentation is important both in supporting the customer’s use cases, but also to prevent us from losing control of our Developer Experience.
The correct answer to this problem is to treat the documentation with the same reverence and care as you do your code, and the best way to do that is to subscribe to the philosophy of “Documentation as Code”.
Documentation as code
This is the view we take of documentation at Upvest. Documentation should be maintained in parallel to the code it describes. That means:
- There should be a 1-to-1 relationship between the set of deployed functionality and the documentation that describes it.
- By extension, we should have the ability to concurrently provide as many versions of the documentation as we do versions of the code).
- We should manage our documentation in the same way we manage code:
- We store our documentation in a plain-text format in a git repository.
- We branch our documentation in line with the development work we’re doing and make pull requests when we want to change it.
- We review pull requests rigorously.
- We use CI/CD:
- We automatically lint and test examples in the documentation.
- We integrate documentation into our software development life cycle:
- A code change isn’t “Done” until it’s documented.
This is what it takes to develop and keep documentation that is up to date and correct. You’ll see that process is remarkably similar to the steps most engineering teams already take for code. Some of this is still an aspiration - we’re not perfect yet, but we’ve made big strides along this path. That’s where all that time and effort over the last 6 months have been taking us.
Staffing up
There are two extra pieces we’ve put in place to make this work. They are:
- Staff within the Developer Experience tribe who own this process and work with the product engineering teams to make sure the right forms of documentation are written to support all use cases.
- Special tooling to make delivering these requirements possible.
I hope the reason why we have staff is self-evident in light of the above. Documentation has to originate with the people who understand the code and the product best, which means the product engineering teams. Ensuring the documentation is structured correctly, follows the correct flow, conforms to a consistent writing style and meets the use cases for the customers is work for a dedicated specialist.
What of the tooling required?
Tooling up
{kind=link}
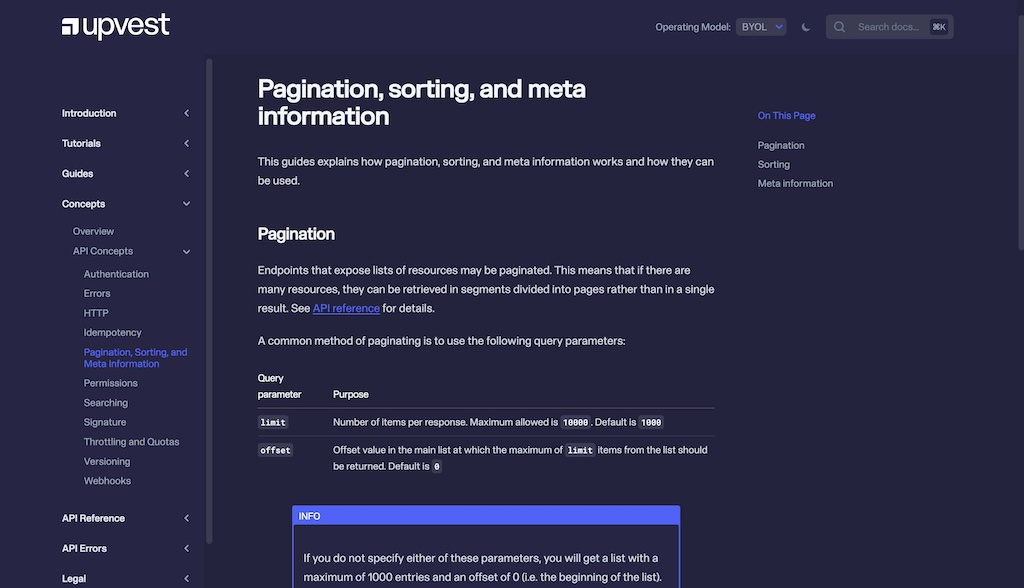
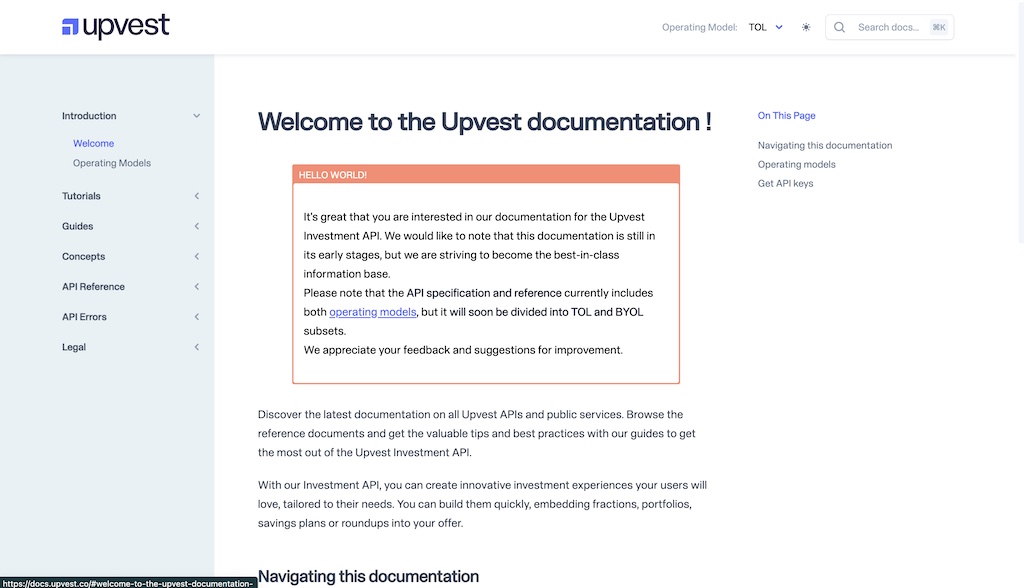
When I arrived at Upvest, the documentation already existed in a GitHub repository, alongside the OpenAPI specification. We were already on the right track. What we lacked was a little organisational discipline around maintaining documentation in line with the deployed code, and the tooling to make that possible. At the time we used Hugo, a very common piece of Open Source static-site generation software. Hugo is a fine and flexible piece of software. We still use Hugo to run this blog, for example. However, making Hugo meet our requirements would have required a significant investment of time and money in custom engineering (and more importantly in finding and hiring engineers to support that). In particular, we wanted:
- Within a single portal support:
- Multiple versions of the documentation tree.
- Generated OpenAPI reference material, tied to a version.
- Different access rights for different versions (Some internal to Upvest, some shared with specific partners, some in public)
- Multiple, switchable operating models, within a single version, shape the documentation and OpenAPI spec to a customer type.
- An engine that understands Git branches and revisions and can act directly on them.
- A management tool to control what is published and who can access it.
- In-line user feedback and analysis.
That’s quite the shopping list, and both the risk and opportunity cost of committing to developing that ourselves were unattractive. I’ve looked at many OpenAPI-based tools and generic documentation tools in my time. Many of them can deliver other requirements we have, but not this exact set. Often they solve problems in quite generic ways, that don’t really fit our use case or give us the experience we want.
Luckily we were introduced to an ambitious startup company with a product that was close to being ready for production use, and similar ambitions around “Documentation as code”. Doctave proved to be very open to the idea of working directly with us to be their first customer in production. Throughout 2022 we built an excellent working relationship that’s seen their documentation platform grow to meet our needs. Not only have we successfully launched our public documentation, but Doctave has opened up a beta program to other customers too.Today, Doctave meets all of the requirements listed above and supports our product engineering teams with live previews of the documentation they’re working on and my tribe with the management tools we need.
Doctave were instrumental in achieving the documentation goals I set out in 2022, and I couldn’t be happier to endorse both the company and their tools. We look forward to our future together!
Summing up
That’s a huge swathe of text. If you made it this far, congratulations. I hope it gives you some food for thought about how and why to do a good job of documenting your software.
I cannot claim to have originated many of these ideas. I’ve read a lot. I’ve worked with top-notch teams, and I’ve learned the hard way what works and what doesn’t.
At Upvest, we’re still near the beginning of our journey, there’s a lot more work for us to do, but the principals, people, processes and tooling are in place. I’m proud of the start we’ve made, and all of the people who’ve contributed to it.